2.2.1a Los tipos carácter
§1 Presentación:
En este capítulo abordamos la importante cuestión de como son representados internamente los caracteres alfabéticos y numéricos (cifras), en los ordenadores en general y en el lenguaje C++ en particular. Describiremos los sistemas de codificación utilizados más frecuentemente, junto con una pequeña introducción a su historia (informática) y evolución, comenzando por el sistema ASCII por ser el más conocido.
§2 Juegos de caracteres
Recuerde que cuando un texto informático utiliza las
expresiones juego de caracteres
("Character set") o codificación de caracteres
("Character encoding"), se refiere siempre a una convención (norma)
para relacionar una secuencia de octetos con una secuencia de glifos (marcas o
dibujos en un papel o en una pantalla)
denominados genéricamente caracteres, que corresponden a letras, símbolos,
cifras o ideogramas de un sistema de escritura. En el interior de la
máquina, esta correspondencia entre glifos y octetos, se materializan en una tabla denominada
página
de códigos ![]() . Recuerde también que un determinado juego de caracteres se refiere
generalmente a un idioma (aunque no siempre), y no
tiene porqué contener todos los caracteres y signos del idioma.
. Recuerde también que un determinado juego de caracteres se refiere
generalmente a un idioma (aunque no siempre), y no
tiene porqué contener todos los caracteres y signos del idioma.
Es interesante observar que desde el punto de vista de la codificación de caracteres, la correspondencia entre octetos y glifos es muy genérica, en el sentido en que por ejemplo, un octeto determinado puede corresponder con la letra latina "A" mayúscula, pero no contiene ninguna indicación o detalle sobre su representación, como tipo de letra a utilizar, tamaño, color, o cualquier otra característica tipográfica que pudiera utilizarse en la representación de dicho carácter. Esos detalles no corresponden a la capa de software encargada de la codificación, sino a la que gobierna la interfaz hombre-máquina.
Actualmente las diversas culturas vivas del mundo utilizan unos 30 juegos de caracteres distintos,
algunos de los cuales sirven a más de una lengua. Como el romano, utilizado
en Europa occidental y otros países del mundo, o el cirílico, utilizado en
países eslavos (![]() Juegos de caracteres).
Básicamente existen dos tipos: alfabéticos
e ideográficos.
Los primeros corresponden a lenguas en las que existe el concepto de palabras
formadas por caracteres del alfabeto. En este caso, los caracteres se
denominan letras, símbolos de puntuación o cifras (según representan). Los segundos corresponden a lenguas en las que una idea
u objeto son descritos mediante un solo glifo, que en este caso se denomina
ideograma.
Juegos de caracteres).
Básicamente existen dos tipos: alfabéticos
e ideográficos.
Los primeros corresponden a lenguas en las que existe el concepto de palabras
formadas por caracteres del alfabeto. En este caso, los caracteres se
denominan letras, símbolos de puntuación o cifras (según representan). Los segundos corresponden a lenguas en las que una idea
u objeto son descritos mediante un solo glifo, que en este caso se denomina
ideograma.
El tipo char nació en el primitivo C de K&R, y fue diseñado
para contener un tipo especial de dato: los cracteres alfanuméricos del idioma inglés-americano. Teniendo en mente los
caracteres que se utilizaban en la informática de la época, se consideró
suficiente asignarle un espacio de almacenamiento de 1 byte. Esta es
precisamente la definición ANSI de byte en C y C++: la memoria requerida para
almacenar un carácter. En consecuencia, en estos idiomas siempre se cumple que sizeof(char) == 1
(![]() 4.9.13 ).
4.9.13 ).
§3 El código ASCII
Como su propio nombre indica, ASCII (American Standard Code for Information Interchange), tiene origen americano, en el instituto ANSI [1]. El ASCII es simplemente una convención para codificar un conjunto de 128 caracteres (letras, números y símbolos), numerados del 0 a 127. Este número se debe a que emplea sólo 7 bits (27 == 128), algo que parecía suficiente en la época en que se propuso el estándar. Mucha gente cree que el código ASCII tiene 256 caracteres (numerados del 0 al 255), que es la capacidad de los 8 bits de un Byte, pero lo cierto es el denominado "ASCII puro", también conocido como US-ASCII (técnicamente es el ANSI X3.4-1968), se compone de sólo 7 bits y 128 caracteres (rango 00h-7fh si lo expresamos en hexadecimal). El primero es el carácter nulo, y tiene el número 0; el último es el 127.
En los 128 caracteres del código ASCII original se encuentran las letras del
alfabeto inglés (mayúsculas y minúsculas), los números, y algunos signos
comunes (espacio en blanco, paréntesis, corchetes, suma y resta, dólar,
porcentaje, etc.) además de otros como retorno de carro, tabulador, campana,
etc. Estos últimos, que eran necesarios para controlar el
funcionamiento de los antiguos teletipos, ocupan las 32 primeras posiciones y
la última, y se denominan precisamente por eso caracteres
de control o no imprimibles.
Puesto que no representan ninguna letra ni signo de puntuación, se designan
mediante nemónicos (NULL, NAK, CR, NL, Etc. [5]).
Ver nota a continuación ![]() .
.
|
Juego de caracteres US-ASCII
|
Leyenda: el valor Hexadecimal se
encuentra entrando en la fila y columna. Por ejemplo, el carácter
"A" está en fila 4 columna 1, luego su valor hexadecimal es 41 = 41h (![]() 2.2.4b).
El valor decimal se ha incluido debajo de cada carácter (en color azul), para
la "A" es 65. Los caracteres no representables se han indicado
por sus nemónicos (en color verde). Al carácter "espacio" le
corresponde el decimal 32 (20h).
2.2.4b).
El valor decimal se ha incluido debajo de cada carácter (en color azul), para
la "A" es 65. Los caracteres no representables se han indicado
por sus nemónicos (en color verde). Al carácter "espacio" le
corresponde el decimal 32 (20h).
Nota: la tabla adjunta incluye los nombres completos y valor decimal de algunos acrónimos muy utilizados en textos informáticos. La columna "Gen." señala la forma en que puede generarse el carácter de control desde el teclado.
| Acrónimo | Gen. |
Nombre completo |
ASCII |
Comentario |
| NUL | Ctrl-@ | Null | 0 | Carácter nulo; un
carácter como los demás, que puede ser definido mediante '\0'. |
| SOH | Ctrl-A | Start of Header | 1 | |
| STX | Ctrl-B | Start of Text | 2 | |
| ETX | Ctrl-C | End of Text | 3 | |
| EOT | Ctrl-D | End of Transmission | 4 | |
| ENQ | Ctrl-E | Enquiry | 5 | |
| ACK | Ctrl-F | Acknowledge | 6 | |
| BEL | Ctrl-G | Bell | 7 | Señal acústica que sonaba en los teletipos para recabar atención del operador. |
| BS | Ctrl-H | Back Space | 8 | Retroceso/retorno de carro |
| HT | Ctrl-I | Horizontal Tab | 9 | Tabulación horizontal |
| LF/NL | Ctrl-J | Line Feed/New Line | 10 | Salto de línea / Nueva línea (espacio vertical). Representado por el dígrafo \n en la mayoría de lenguajes y textos informáticos. |
| VT | Ctrl-K | Vertical Tab | 11 | Tabulación vertical |
| FF | Ctrl-L | Form Feed | 12 | Salto de página |
| CR | Ctrl-M | Carriage Return | 13 | Retorno de carro de impresión. También suele ser representado por el dígrafo \r |
| SO | Ctrl-N | Shift Out | 14 | |
| SI | Ctrl-O | Shift In | 15 | |
| DLE | Ctrl-P | Data Link Escape | 16 | |
| DC1 | Ctrl-Q | Device Control 1 | 17 | También conocido como XON [6] |
| DC2 | Ctrl-R | Device Control 2 | 18 | |
| DC3 | Ctrl-S | Device Control 3 | 19 | También conocido como XOFF [6] |
| DC4 | Ctrl-T | Device Control 4 | 20 | |
| NAK | Ctrl-U | Negative Acknowledge | 21 | |
| SYN | Ctrl-V | Synchronous Idle | 22 | |
| ETB | Ctrl-W | End Transmission Block | 23 | |
| CAN | Ctrl-X | Cancel | 24 | |
| EM | Ctrl-Y | End of Medium | 25 | |
| SUB | Ctrl-Z | Substitute | 26 | |
| ESC | Ctrl-[ | Escape | 27 | |
| FS | Ctrl-\ | File Separator | 28 | |
| GS | Ctrl-] | Group Separator | 29 | |
| RS | Ctrl-Ctrl | Record Separator | 30 | |
| US | Ctrl-_ | Unit Separator | 31 | |
| SP | Space | 32 | Espacio horizontal | |
| DEL | Delete / rubout | 127 | ||
| CHAR | Character | 0 - 127 | Cualquier carácter US-ASCII | |
| CTL | 0-31+ 127 | Cualquier carácter de control | ||
| UALPHA | 65 - 90 | Cualquier mayúscula "A"..."Z" | ||
| Ctrl | Control | 94 | Representado por el símbolo ^ | |
| LOALPHA | 97 -122 | Cualquier minúscula "a"..."z" | ||
| ALPHA | Cualquier letra, mayúscula o minúscula | |||
| DIGIT | 48 - 57 | Cualquie dígito "0"..."9" |
§3.1 El ASCII extendido
Con la internacionalización de los ordenadores, se cayó en la cuenta que los 128 caracteres del US-ASCII no eran suficientes para trabajar con los signos de otros idiomas (tildes; signos especiales como las interrogaciones o exclamaciones de apertura; letras como la eñe, la cedilla y otras), de modo que los fabricantes comenzaron a usar un conjunto de caracteres ASCII ampliado de 8 bits (256 caracteres), que además coincidía con el tamaño de palabra de los procesadores de la época. Las 128 posiciones primeras seguían conteniendo el US-ASCII, pero en los 128 caracteres adicionales, que constituyen lo que se denomina ASCII extendido, añadieron todas las letras y signos especiales de uso común en lenguas de Europa occidental, como el español, francés o alemán.
Por desgracia, en aquel momento no se siguieron estándares únicos, ni hubo
una decisión internacional al respecto. Cada fabricante de ordenadores y
software usó su propio código seudo-ASCII en variaciones nacionales o de
sistema operativo, construyendo sus propias páginas de códigos (§5
![]() )
sin pensar en los problemas que esto acarrearía a la
informática del futuro, con lo que se originó una pequeña "Babel"
de sistemas de codificación de caracteres que perdura hasta hoy.
)
sin pensar en los problemas que esto acarrearía a la
informática del futuro, con lo que se originó una pequeña "Babel"
de sistemas de codificación de caracteres que perdura hasta hoy.
Actualmente, el juego de caracteres ASCII
extendido de los PC es distinto en MS-DOS y MS-Windows, distinto a
su vez del "ASCII Macintosh" y del ASCII Unix; del de algunos
sistemas IBM, y desde luego de otros muchos sistemas operativos antiguos y
modernos [2]. Algunas de estas versiones de ASCII
extendido se han estandarizado. Ver a continuación el Estándar ISO 8859
![]() .
.
Por su parte, en la época del desarrollo del C original (la primera edición del libro de K&R es de 1978), ya se utilizaba el ASCII extendido, y por supuesto, las 256 posibilidades de un byte eran suficientes para albergar los caracteres definidos en el Estándar, por lo que al tipo char se le asignó 1 octeto.
§3.2 Evolución del ASCII
De entre todos los sistemas ASCII de 8 bits (SBCS "Single Byte Character Sets"), los que han alcanzado mayor fortuna han sido dos: El que se incorporó por defecto en los PCs de IBM en la década de los 80, y posteriormente, el de los sistemas Windows 9x de MS.
El juego de caracteres del PC, incorporó símbolos especiales para representar visualmente (en la pantalla) los caracteres de control que hasta entonces no tenían representación gráfica. El juego de caracteres extendido se muestra en la tabla adjunta.
|
§4.2a Juego de caracteres extendidos ASCII-PC |
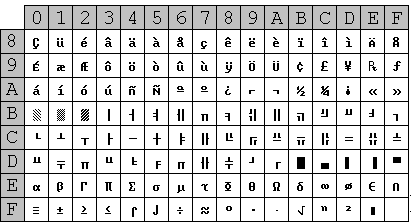 |
En lo que respecta a Microsoft, el
gigante de la informática incorporó en sus sistemas Windows 9x un juego de
caracteres bastante adaptado a la mayoría de los alfabetos
occidentales. Posteriormente implementó en sus sistemas NT y sucesores,
un sistema denominado Unicode que utiliza
16 bits para representar los caracteres; sus 65.537 posibilidades permiten
representar los de todas las lenguas del mundo (![]() 2.2.1a2).
2.2.1a2).
Nota: en las páginas siguientes se detallan las características de los sistemas de codificación multibyte, que representan el último paso evolutivo de los sistemas SBCS.
§3.2b El cojunto de caracteres ASCII extendido tal como se
ven en un sistema Windows 9x (los caracteres marcados _,
no tienen representación gráfica visible en MS Windows 98 con I. Explorer 5.50).
 |
§3.2c Juego de caracteres ASCII extendido tal como son generados en su computadora
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8 | € | | ‚ | ƒ | „ | … | † | ‡ | ˆ | ‰ | Š | ‹ | Œ | | Ž | |
| 9 | | ‘ | ’ | “ | ” | • | – | — | ˜ | ™ | š | › | œ | | ž | Ÿ |
| A | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | ® | ¯ | ||
| B | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| C | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| D | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| E | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| F | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
§3.3 A continuación se muestra una
calculadora interactiva [4] para representar los caracteres
ASCII y sus valores numéricos correspondientes en los diversos
sistemas: Decimal, Hexadecimal y Octal (Válido para los
navegadores Netscape 3+ y MS IE 4+):
§4 Página de códigos
Los juegos de caracteres, ya sean ASCII, Unicode o de cualquier tipo, se materializan dentro de la máquina en unas tablas denominadas páginas de códigos, que establecen la relación entre cada glifo y su valor numérico [8]. Las páginas de códigos pueden ser cualquiera, incluso construidas por el usuario, pero las utilizadas más frecuentemente están estandarizadas. Existen dos tipos:
-
ACP ("ANSI Code Pages") Las que han sido estandarizadas por el Instituto de Estándares Americano. Por ejemplo: la página de códigos ANSI 1252 corresponde al Inglés-Americano y a la mayoría de lenguas de Europa occidental.
-
OCP ("OEM Code Pages") Son propuestas por fabricantes u organizaciones no oficiales (OEM significa "Original Equipment Manufacturer"). Por ejemplo, la OEM 932 corresponde al juego Kanji de caracteres Japoneses (
 2.2.1a0),
mientras que el OEM 949 representa un juego de caracteres Coreano.
2.2.1a0),
mientras que el OEM 949 representa un juego de caracteres Coreano.
Generalmente las páginas
de código son mantenidas por el Sistema Operativo, y existen en dos
versiones: para caracteres normales y para caracteres anchos. Los
programas C/C++ las utilizan de dos modos: forma controlada explícitamente por el
programador en runtime (![]() 5.2), o controlada por el propio
compilador que selecciona unas páginas por defecto que son cargadas desde el Sistema
anfitrión como parte de las rutinas de inicio.
5.2), o controlada por el propio
compilador que selecciona unas páginas por defecto que son cargadas desde el Sistema
anfitrión como parte de las rutinas de inicio.
El MS-DOS, quizás el primer Sistema Operativo que llegó a ser verdaderamente universal, utilizó distintas páginas de código con una nomenclatura propia para extender este Sistema a entornos distintos del Inglés-Americano. Por ejemplo:
437 Inglés-USA (del PC original IBM)
737 Griego
862 Hebreo
863 Franco-Canadiense
850 Multi-Lingual (Latín-1)
865 Nórdico
860 Portugués
852 Eslavo (Latín-2)
A su vez, el Estándar ISO 8859 establece 15 páginas de código, de las que se han reservado diez para las lenguas que utilizan un juego de caracteres de raíz latina [7]:
|
ISO 8859-1 (Latin-1) Europa
occidental ISO 8859-5 Cirílico |
ISO 8859-9 (Latin-5) Europa oriental + Turquía ISO 8859-10 (Latin-6) ISO 8859-11 Latin/Thai ISO 8859-13 (Latin-7) ISO 8859-14 (Latin-8) Celta ISO 8859-15 (Latin-9) ISO 8859-16 (Latin-10) |
Observe que un lenguaje natural utiliza siempre la misma página de códigos (la que contiene todos sus caracteres y signos de puntuación), pero una página de códigos no tiene porqué estar relacionada únicamente con un lenguaje. Por ejemplo, la página ANSI 1252 puede ser utilizada por los lenguajes Inglés, Español y Francés porque contiene todos los caracteres utilizados en estas lenguas.
Nota: Windows XP y Windows 2000 disponen de la utilidad charmap, que permite ver los caracteres disponibles en una fuente seleccionada, así como mostrar los juegos de caracteres: Windows, DOS y Unicode. Puede copiar caracteres individuales o un grupo de caracteres al Portapapeles y pegarlos en cualquier programa que pueda mostrarlos. También permite buscar caracteres por el nombre de carácter Unicode o un subgrupo Unicode (por ejemplo, flechas u operadores matemáticos).
Como se ha señalado anteriormente (§4.1
![]() ),
las páginas de código de caracteres normales
tienen 256 posiciones, aunque la mayoría comparte 128 posiciones con el juego
de caracteres ASCII (el rango 0x00-0x7F). En cambio, las páginas de
caracteres anchos son muy grandes (64 K entradas), aunque no suelen cargarse
completas, solo las primeras 256 posiciones y ciertas zonas correspondientes a
los rangos que utilizará el programa [3].
),
las páginas de código de caracteres normales
tienen 256 posiciones, aunque la mayoría comparte 128 posiciones con el juego
de caracteres ASCII (el rango 0x00-0x7F). En cambio, las páginas de
caracteres anchos son muy grandes (64 K entradas), aunque no suelen cargarse
completas, solo las primeras 256 posiciones y ciertas zonas correspondientes a
los rangos que utilizará el programa [3].
Como veremos al tratar de la
internacionalización de los programas (![]() 5.2), muchas funciones de la Librería Estándar C++ para
manipulación de caracteres normales y caracteres anchos, adaptan su
comportamiento a la página de códigos correspondiente que haya sido cargada.
5.2), muchas funciones de la Librería Estándar C++ para
manipulación de caracteres normales y caracteres anchos, adaptan su
comportamiento a la página de códigos correspondiente que haya sido cargada.
![]() Recordar que la Librería
Estándar C++ (
Recordar que la Librería
Estándar C++ (![]() 5)
dispone de funciones especiales para determinar ciertas características de
cualquier carácter. Por ejemplo, si es imprimible (representable
gráficamente); si es un dígito o carácter alfabético; si es ASCII,
etc. Ver: isalpha(); isascii(); iscntrl();
isdigit(); isgraph(); islower(); etc.
5)
dispone de funciones especiales para determinar ciertas características de
cualquier carácter. Por ejemplo, si es imprimible (representable
gráficamente); si es un dígito o carácter alfabético; si es ASCII,
etc. Ver: isalpha(); isascii(); iscntrl();
isdigit(); isgraph(); islower(); etc.
[1] ANSI
(American National Standards Institute). Este instituto, fundado en 1918,
es una organización compuesta por unos 1300 miembros, incluyendo las
compañías de informática más importantes. Se encarga de redactar los
estándares para USA. ![]() http://web.ansi.org.
A su vez es miembro de la Organización Internacional de Estandarización ISO
(International Standards Organization). Fundada en 1946, agrupa 89 países miembro, y es
responsable de los estándares a mundiales en muchas áreas, incluyendo
electrónica e informática.
http://web.ansi.org.
A su vez es miembro de la Organización Internacional de Estandarización ISO
(International Standards Organization). Fundada en 1946, agrupa 89 países miembro, y es
responsable de los estándares a mundiales en muchas áreas, incluyendo
electrónica e informática. ![]() http://www.iso.ch/
http://www.iso.ch/
[2] El libro de Mackenzie ![]() "Coded Character Sets" es "La Biblia"
al respecto de la historia de este juego de caracteres.
"Coded Character Sets" es "La Biblia"
al respecto de la historia de este juego de caracteres.
[3] No tiene sentido cargar el conjunto Japones de caracteres Kanji, que tiene decenas de miles de entradas, si no vamos a utilizar este idioma en nuestro programa. A título de ejemplo, señalemos que el documento Unicode que describe el juego de caracteres Latino básico ocupa 126 KB. mientras que el documento análogo para el juego de ideogramas Kanji ocupa 5.316 MB.
[4] Reproducido aquí por cortesía de Juan Soulie <juan@soulie.com>
[5] Cuando se trata de escritura
normal se utilizan estos nemónicos. Por ejemplo, es corriente ver escrito
algo como "Salir con ESC" para designar la tecla que produce este
carácter. En cambio, cuando se trata de representarlos en el texto del
código fuente, se utilizan las denominadas secuencias
de escape (![]() 3.2.3e)
3.2.3e)
[6] Estos caracteres tienen un significado especial en el caso de transmisiones serie cuyo control de flujo se realiza por software: la recepción de un carácter XOFF en el transmisor, es una petición del receptor para que suspenda momentáneamente el flujo transmitido, mientras que XON tiene el significado contrario.
[7] Las páginas de códigos "Latin" del estándar ISO no guardan ninguna relación con las páginas de código del MS-DOS.
[8] En el texto hemos empleado la palabra "glifo" (figura o signo). Por ejemplo, la figura que en nuestro idioma representa a la letra A mayúscula, para referirnos a la imagen que representa a las letras, cifras o signos de puntuación, pero observe que no nos referimos a ninguna forma concreta. Piense por ejemplo en que la representación en mayúscula de la primera letra del alfabeto ("A") puede tener múltiples formas concretas. A, A, A, A, A, etc. Las posibilidades concretas de representación dependen entre otros factores, del juego de fuentes ("fonts") disponibles en el ordenador.