2.2.1a0 Sistemas de codificación
§1 Evolución de los sistemas de codificación
Además de los problemas esbozados en el capítulo anterior (![]() 2.2.1a), derivados de representar los caracteres de lenguas europeas distintas del
inglés-americano, la difusión de la informática a culturas de raíz no latina puso rápidamente de manifiesto que 256 caracteres
eran insuficientes para contener los grafos de todas las lenguas. Por ejemplo, el cirílico; el hebreo; el árabe; el griego, y el
japonés por citar algunas [1]. Se hizo evidente la necesidad un sistema con más de 256 posibilidades, lo
que condujo a establecer sistemas de codificación en los que cada carácter ocupaba más de un octeto (al menos ciertos caracteres),
razón por la cual a estos sistemas se les conoce genéricamente como de caracteres anchos.
2.2.1a), derivados de representar los caracteres de lenguas europeas distintas del
inglés-americano, la difusión de la informática a culturas de raíz no latina puso rápidamente de manifiesto que 256 caracteres
eran insuficientes para contener los grafos de todas las lenguas. Por ejemplo, el cirílico; el hebreo; el árabe; el griego, y el
japonés por citar algunas [1]. Se hizo evidente la necesidad un sistema con más de 256 posibilidades, lo
que condujo a establecer sistemas de codificación en los que cada carácter ocupaba más de un octeto (al menos ciertos caracteres),
razón por la cual a estos sistemas se les conoce genéricamente como de caracteres anchos.
La solución adoptada comprende dos grandes grupos: el sistema multibyte (§2
![]() ) y el sistema de caracteres
anchos (§3
) y el sistema de caracteres
anchos (§3 ![]() ), de los
que existen distintas variedades. Generalmente el primero se utiliza en representación externa (almacenamiento) y
comunicaciones, mientras que el segundo es preferido para representaciones internas.
), de los
que existen distintas variedades. Generalmente el primero se utiliza en representación externa (almacenamiento) y
comunicaciones, mientras que el segundo es preferido para representaciones internas.
§2 Sistema multibyte
Si se trata de representar juegos de más de 256 caracteres en almacenamientos externos o en sistemas de transmisión, en los que es importante la economía de espacio y/o ancho de banda, la solución ha consistido en utilizar sistemas de codificación multibyte. Conocidos abreviadamente como MBCS ("Multibyte Character Set").
Como su nombre indica utilizan más de un octeto, pero la anchura de los distintos caracteres es variable según la necesidad del momento. Los caracteres multibyte son una amalgama de caracteres de uno y dos bytes de ancho que puede considerarse un superconjunto del ASCII de 8 bits. Por supuesto una convención de este tipo exige una serie de reglas que permitan el análisis ("Parsing") de una cadena de bytes para identificar cada carácter.
Nota: el juego de caracteres ASCII suele ser un subset de todos los sistemas de codificación
multibyte, de forma que en cualquier página de código (![]() 2.2.1a) MBCS, los caracteres en
el rango 0x00-0x7F son idénticos a los del mismo valor en la página ANSI 1252.
2.2.1a) MBCS, los caracteres en
el rango 0x00-0x7F son idénticos a los del mismo valor en la página ANSI 1252.
Existen distintas versiones de este tipo de codificación que se utilizan en distintas circunstancias:
JIS ("Japanese Industrial Standar"). Es utilizado principalmente en comunicaciones, por ejemplo correo electrónico, porque utiliza solo 7 bits para cada carácter [2]. Usa secuencias de escape para conmutar entre los modos de uno y dos bytes por carácter y para conmutar entre los diversos juegos de caracteres.
Shift-JIS. Introducido por Microsoft y utilizado en el sistema MS-DOS, es el sistema que soporta menos caracteres. Cada byte debe ser analizado para ver si es un carácter o es el primero de un dúo.
EUC ("Extended Unix Code"). Este sistema es utilizado como método de codificación interna en la mayoría de plataformas Unix. Acepta caracteres de más de dos bytes, por lo que es mucho más extensible que el Shift-JIS, y no está limitado a la codificación del idioma japonés. Resulta muy adecuado para el manejo de múltiples juegos de caracteres.
UTF-8 ("Unicode transformation format"). En este sistema, cada carácter se representa mediante una secuencia de 1 a 4 bytes. Aunque en realidad, el número de bits destinados a representar el carácter se limita a un máximo de 21 (el resto son metadatos -información sobre información-). El objeto de estos metadatos es que la secuencia pueda ser interpretada a partir de cualquier posición. Es decir, que de la simple inspección de un trozo, sea posible conocer donde comienza cada carácter y cuantos bytes lo componen. El esquema adoptado es el siguiente:
bytes
bits de datos
representacion interna
1
7
0xxxxxxx
2
11
110xxxxx 10xxxxxx
3
16
1110xxxx 10xxxxxx 10xxxxxx
4
21
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Cada X representa un bit de datos (valor 0/1). En realidad puede decirse que UTF-8 es un sistema de codificación que transforma un caracter multibite (entre 8 y 32 bits) en una secuencia de caracteres simples (8 bits), de ahí su nombre.
Es el esquema utilizado por Unicode (
 2.2.1a2) para almacenar sus caracteres
anchos (de 16 bits). A su vez, los caracteres US-ASCII conservan su mismo esquema cuando se
codifican en UTF-8, por lo que una cadena de caracteres US-ASCII conserva su mismo significado en ambos sistemas (en realidad
UTF-8 fue diseñado para ser compatible hacia atrás con el US-ASCII). El diseño adoptado hace que sea un sistema
auto-sincronizado, lo que significa que de la simple inspección de la cadena puede deducirse cuando empieza y termina cada
carácter. La regla es que si el primer bit es cero, se trata de caracteres de 1 byte de los que solo son significativos los 7
bits siguientes (puro US-ASCII). Si el primer bit es un uno sabemos que es un carácter multibyte. 2 bytes por carácter si la
combinación inicial es 110; tres si 1110, y cuatro bytes por carácter para 11110.
2.2.1a2) para almacenar sus caracteres
anchos (de 16 bits). A su vez, los caracteres US-ASCII conservan su mismo esquema cuando se
codifican en UTF-8, por lo que una cadena de caracteres US-ASCII conserva su mismo significado en ambos sistemas (en realidad
UTF-8 fue diseñado para ser compatible hacia atrás con el US-ASCII). El diseño adoptado hace que sea un sistema
auto-sincronizado, lo que significa que de la simple inspección de la cadena puede deducirse cuando empieza y termina cada
carácter. La regla es que si el primer bit es cero, se trata de caracteres de 1 byte de los que solo son significativos los 7
bits siguientes (puro US-ASCII). Si el primer bit es un uno sabemos que es un carácter multibyte. 2 bytes por carácter si la
combinación inicial es 110; tres si 1110, y cuatro bytes por carácter para 11110.Debido a los esfuerzos de homogenización realizados entre el consorcio Unicode y los comités ISO/IEC ("International Organization for Standardization"/"International Electrotechnical Commission"), el sistema UTF-8 y el ISO/IEC 10646-1:1993 son coincidentes.
UTF-16 y UTF-32 son sistemas de codificación Unicode similar al anterior, aunque en estos casos las secuencias son de 16 y 32 bits respectivamente. Puesto que en el mejor de los casos, un carácter codificado en UTF-8 utiliza 32 bits (4 Bytes), resulta claro que cualquier carácter codificado en UTF-8 requerirá solo 1 grupo de bits si se codifica en UTF-32 o dos, si lo es en UTF-16.
En particular, la palabra de dos bytes que componen una secuencia UTF-16 -que puede ser contenida en un caracter ancho de C/C++-, es capaz de contener todos los caracteres cuya representación numérica ("code point") esté entre 0 y 65.535 (h0000-hFFFF). Este conjunto, conocido como BMP ("Basic Multilingual Plane") permite representar los caracteres de la mayoría de idiomas del mundo.
Cuando la palabra anterior no es suficiente, se requiere otro conjunto de 16 bits adicionales para codificar el carácter. Se dice entonces que se utiliza un par subrogado ("surrogate pair"). Al primer grupo se le denomina subrogado alto ("high surrogate") y al segundo, subrogado bajo ("low surrogate"). Estas representaciones numéricas ("code points") se denominan suplementarias -de las que utilizan 16 bits- y se supone que los caracteres correspondientes no están en el BMP, sino en planos suplementarios.
Si desea más detalles sobre la forma concreta en que se realiza esta descomposición de un "code point" en un par subrogado, puede consultar esta página de la Organización Unicode, donde encontrará incluso una rutina para codificar cualquier valor en UTF-16.
Como punto a destacar, señalemos que UTF-16 es el método empleado para la representación interna de datos en la mayoría de Sistemas Operativos. Por ejemplo, es el caso de Windows XP y Vista, y que al igual que en UTF-8, donde no toda la capacidad de representación de un octeto se utiliza para representar los datos -en el mejor de los casos ser desaprovecha 1 bit (metadato)-, en UTF-16 también es necesario desaprovechar algo la capacidad de representación de los 16 bits para representar metadatos y permitir que de la inspección de una secuencia, pueda saberse si una palabra corresponde a un par subrogado, o representa un caracter en sí misma. El resultado es que para la mayoría de idiomas no se requieren pares subrogados y que en C/C++, puede suponerse casi con seguridad que cada caracter ancho (grupo de 16 bits) codificado en UTF-16 corresponde a un carácter, aunque no simpre cierto. De hecho, si se maneja esta codificación, es necesario asegurarse que el carácter no forma parte de un par subrogado, lo que puede hacerse conociendo que en tal caso, el valor del subrogado alto está siempre comprendido entre los valores 55.296 y 56.319 (hD800-hDBFF), mientras que el subrogado bajo lo está entre 57.343 y 56320 (hDC00-hDFFF), lo que quiere decir que considerados aisladamente, los caracteres anchos comprendidos en este rango no tienen significado de forma aislada y deben ser interpretados con el adyacente como un solo caracter.
Puesto que una palabra de 16 bits puede representar 216 = 65.536 valores distintos (65.537 si contamos el cero), observamos que UTF-16, utiliza 1.023 de ellas como metadatos para subrogados bajos (hDBFF - hD800) y otras 1.023 para los subrogados altos (hDFFF - hDC00). Lo que representa aproximadamente un 3.12% del total.
§2.1 Codificación JIS
Como sugiere su nombre, fue diseñado específicamente solventar los problemas de representación de la escritura japonesa. En este sistema, una frase puede contener caracteres de hasta cuatro sistemas de escritura distintos: el sistema Kanji, que tiene decenas de miles de caracteres representados por dibujos basados en ideogramas chinos. Los sistemas Hiragana y katakana son silábicos; cada uno contiene aproximadamente 80 sonidos que son también representados por ideogramas. Finalmente el sistema Roman, que contiene 95 letras, dígitos y signos de puntuación es lo más parecido a la escritura simbólica occidental (basada en letras).
En la figura adjunta [3] se muestra una frase en japonés que utiliza los cuatro sistemas de escritura señalados
Los distintos sistemas han señalado con distinto tono de fondo. Traducción: "Los métodos de codificación como JIS pueden representar mezclas de texto Japonés e Inglés".
Existen diversos juegos de caracteres de este idioma (incluso se utilizan los caracteres ASCII). Aunque no existe un sistema de codificación del japonés que sea universalmente admitido, algunos son más generales: JIS C 6226-1978; JIS X 0208-1983; JIS X 0208-1990; JIS X 0212-1990; JIS-ROMAN (este último es el juego de caracteres ASCII).
Los sistemas JIS utilizan caracteres de uno y dos bytes de ancho; el paso de un tipo a otro se señala mediante una secuencia de escape que pertenece al esquema de codificación y no forman parte del mensaje propiamente dicho. Ejemplo [3]:
|
Estado inicial: ASCII de 1 byte |
Cambio a Kanji |
Juego de caracteres Kanji. |
Cambio a ASCII |
Juego de caracteres ASCII de 1 byte |
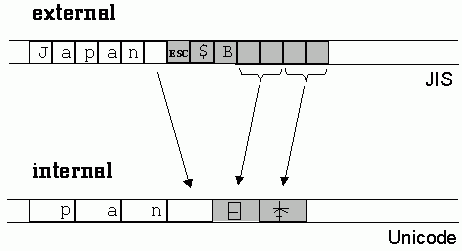
Las secuencias de escape, también denominadas "de control", no tienen representación gráfica, y obligan al analizador sintáctico que examina el mensaje a mantener un control de estado, que es activado cada vez que encuentra una secuencia de control. En el ejemplo anterior el estado inicial es ASCII de 1 byte por carácter. Al encontrar la secuencia <ESC>$B es interpretada como cambio al sistema Kanji, de forma que a partir de ahí cada dos bytes se interpretan como un carácter del conjunto JIS X 0208. A llegar a la secuencia <ESC>(B se interpreta como cambio al sistema ASCII de un byte por carácter, y así sucesivamente [4].
Estos sistemas de codificación no son muy eficientes para almacenamiento interno o para proceso de la información, razón por la que suelen ser utilizados para almacenamiento externo y como medio de compartir información entre un programa y el mundo exterior. Puede ocurrir que si el mensaje incluye cambios muy frecuentes la información de codificación supere a la del propio mensaje (cuando está en formato 2 bytes por carácter la secuencia de control ocupa 6 bytes). Además tiene el inconveniente que no puede ser leído en cualquier orden, por ejemplo del final al principio o comenzando en cualquier punto.
§2.2 Codificación Shift-JIS
A pesar de su nombre este sistema no tiene ninguna conexión con el anterior. Aquí la información de codificación acompaña a cada byte, de forma que él mismo indica si debe ser interpretado como un carácter aislado o el primero de un dúo, conocidos como byte de cabeza y de cola ("Lead" byte y "Trail" byte). La información está codificada en el propio valor porque el rango de valores posibles está distribuido en varios significados:
|
Rango |
||
| Hex. | Dec. | Significado |
| Carácter de 1 byte del conjunto JIS Roman | ||
| Carácter Katakana | ||
| |
Byte de cabeza ("Lead") de un carácter ancho del conjunto JIS X 0208-1990. | |
| Byte de cola ("Trail") del caso anterior. | ||
Este sistema de codificación es más compacto que el JIS, aunque no puede representar tantos caracteres como aquél. En concreto no puede representar el conjunto JIS X 0212-1990 que contiene más de 6.000 caracteres.
§2.3 Codificación EUC
Como sugiere su nombre, el sistema EUC ("Extended Unix Code") es utilizado como método de codificación interna en plataformas Unix. Fue desarrollado como un sistema general capaz de manejar múltiples sistemas de codificación en cualquier flujo de datos, sin que esté por tanto ligado necesariamente a la representación de la escritura Japonesa.
Es mucho más extensible que el Shift-JIS, porque permite caracteres de más de dos bytes de ancho. Aunque no está ligado necesariamente a la representación de la escritura Japonesa sirve naturalmente para este propósito. A continuación se muestra el esquema de codificación utilizado por EUC para para esta lengua:
|
Rango |
||
| Hex. | Dec. | Significado |
| Carácter de 1 byte del conjunto JIS Roman | ||
| La mitad de un carácter del conjunto JIS X0208-1990. El segundo byte del carácter debe estar en el mismo rango | ||
8E |
142 |
Cualquier byte de este valor debe estar seguido de un byte en el rango A1-DF, que representa un carácter del conjunto Katakana. |
8F |
143 |
Cualquier byte de este valor debe ir seguido de dos bytes adicionales en el rango A1-FE, que representan un carácter del conjunto JIS X 0212-1990, que como hemos indicado contiene más de 6.000 caracteres. |
Como puede verse en los dos últimos casos, los caracteres 0x8E y 0x8F
funcionan en cierta manera como las secuencias de control del sistema JIS, en
el sentido que introducen un cambio de codificación, aunque se diferencian de
aquellas en que estas deben preceder a cada carácter ancho del mensaje (no
solo al primero de una secuencia). Por esta razón se considera que cada
carácter multibyte del sistema EUC es auto-contenido y no depende de ningún control de estado.
§3 Sistema de caracteres anchos
Los sistemas de codificación multibyte son bastante eficientes en cuanto al espacio de almacenamiento utilizado, pero son poco prácticos para su empleo como medio de almacenamiento en programas y cuando se daba realizar sobre ellos cualquier computación. En estos casos es preferible utilizar un esquema en el que todos los caracteres tengan el mismo ancho, aun cuando esto suponga utilizar un cierto espacio adicional. Este sistema de codificación es conocido como de caracteres anchos, del que existen dos versiones básicas: sistemas que utilizan dos bytes, conocidos como DBCS ("Double Byte Character Set"), y sistemas que utilizan más de dos.
| ISO 10646.UCS-2 | Caracteres de 16 bits (2 Bytes) |
| ISO 10646.UCS-4 | Caracteres de 32 bits (4 Bytes) |
| ISO-10646-UCS-1 | Caracteres de 16 bits (2 Bytes). Más conocido como Unicode
( |
El sistema de caracteres anchos DBSC ha sido la solución adoptada por los compiladores C y C++ para representar
aquellos conjuntos de caracteres a los que no bastan las posibilidades del sistema ASCII extendido, aunque cabe destacar
que la estrategias utilizadas en uno y otro lenguaje difieren ligeramente (más detalles en
![]() 2.2.1a1).
2.2.1a1).
La representación en el fuente es la siguiente:
char ch = 'a'; // constante carácter normal
char* str = "abc"; // cadena de caracteres normales
wchar_t wch = L'a'; // constante carácter-ancho
wchar_t* wstr = L"abc"; // cadena de caracteres anchos
§4 Conversión entre sistemas multibyte y de caracteres anchos
Debido a que los caracteres anchos se emplean generalmente para representación interna, y los multibyte para la representación externa, las operaciones de entrada/salida suelen implicar un proceso de conversión entre ambos sistemas de codificación. Un caso frecuente lo constituyen los procesos de lectura y escritura de ficheros. Estos últimos contienen generalmente caracteres multibyte, y cuando se lee un fichero, sus caracteres deben ser convertidos en caracteres anchos y situados en un almacenamiento interno donde puedan ser procesados. Evidentemente el sistema de caracteres anchos debe tener anchura suficiente para contener el carácter más ancho del sistema multibyte. En cambio, todas las secuencias de escape pueden ser eliminadas. La figura adjunta [3] muestra esquemáticamente el proceso de convertir un fichero de codificación JIS al sistema Unicode de caracteres anchos.
 |
Nota: La Librería Estándar C++ dispone de algunas herramientas para realizar este tipo de
conversiones (![]() 5.2.1).
5.2.1).
[1] El sistema de escritura tradicional japonés denominado Kanji utiliza decenas de miles de caracteres basados en los ideogramas chinos.
[2] Por razones históricas muchos sistemas de comunicación por Internet utilizan solo 7 bits en sus transmisiones, ya que la red fue desarrollada utilizando el juego de caracteres US-ASCII. Generalmente los sistemas utilizan internamente 8 bits, pero el último es descartado.
[3] Del manual Borland "Standar C++ Library Help".
[4] El sistema es análogo al utilizado por muchos procesadores de texto para almacenar información sobre tipo y tamaño de letra, color de fondo, subrayado, etc.
[5] ISO/IEC son las siglas de