4.4.6b Sobre el rendimiento
§1 Preámbulo
En algunos sentidos, C++ es un lenguaje de muy bajo nivel (incluso permite insertar instrucciones ensamblador directamente
![]() 4.10), por lo
que hay ocasiones en que el programador necesita habérselas con cuestiones muy de detalle y conocer íntimamente el
funcionamiento de los mecanismos subyacentes. Sobre todo si pretende entender mínimamente el porqué de ciertas cosas y la
terminología utilizada en los textos de programación. En este capítulo incluimos algunos conceptos que sin ser estrictamente
cuestiones C++ sin duda le ayudarán en su tarea de habérselas con ese pequeño monstruo.
4.10), por lo
que hay ocasiones en que el programador necesita habérselas con cuestiones muy de detalle y conocer íntimamente el
funcionamiento de los mecanismos subyacentes. Sobre todo si pretende entender mínimamente el porqué de ciertas cosas y la
terminología utilizada en los textos de programación. En este capítulo incluimos algunos conceptos que sin ser estrictamente
cuestiones C++ sin duda le ayudarán en su tarea de habérselas con ese pequeño monstruo.
§2 Carga y descarga de funciones
Es importante conocer que C y C++ son lenguajes orientados a pila y estructurados alrededor del concepto de función; el funcionamiento de ambos está íntimamente relacionado. Desde el punto de vista del programador, la invocación de una función es una sentencia del tipo:
func1();
aunque finalmente aparece como una llamada a la dirección donde se encuentra el recurso correspondiente. En ensamblador sería algo así:
call 0x4000000
En realidad, lo que ocurre en las tripas de la máquina cuando se invoca una función es un proceso bastante complejo, ya
que la invocación, ejecución y retorno de una función no es solo cuestión de algoritmo. También hay datos de entrada bajo la
forma de los argumentos "pasados" a la función (en base a los cuales el código realizará cierta computación
![]() 4.4.5) y datos de salida en forma
del valor "devuelto".
4.4.5) y datos de salida en forma
del valor "devuelto".
Nota: observe que si el la llamada a funciones solo interviniese el código, el mecanismo de invocación quedaría reducido a un salto "jump" al punto de entrada del nuevo bloque de código.
El asunto es que, aparte de seguir el camino ("path") de ejecución adecuado, el programa necesita preparar el entorno de ejecución (datos) para el nuevo trozo de ejecutable y apuntar él mismo cierta información que le permita volver al punto de partida. Para entender el mecanismo, es imprescindible desterrar la idea del argumentos "pasados" o valores "devueltos" como datos que van y vienen desde/hacia la función invocante a/desde la función invocada.
La anterior es una imagen didáctica, diríamos de "alto nivel" y adecuada para una explicación básica de los mecanismos de invocación de funciones. Pero como decíamos al principio, C++ es en ciertos aspectos un lenguaje de bajo nivel (pegado a la máquina) y si se quiere entender y manejar con éxito (en especial si se utilizan programas con módulos compilados en otros lenguajes), es fundamental una mirada más cercana al proceso.
En realidad no existe en absoluto algo como "paso" de argumentos (ni por valor ni por referencia). Realmente los
datos (los argumentos actuales) de la función invocante se copian [6] a una zona de memoria que se
crea ex-profeso en la pila (![]() 1.3.2), denominada marco de activación o marco de pila ("Stack
frame").
1.3.2), denominada marco de activación o marco de pila ("Stack
frame").
Nota: por extensión también se denomina a veces registro de activación (aunque no debería
decirse así). La razón es que la dirección de comienzo de esta zona queda almacenada un registro del procesador denominado por
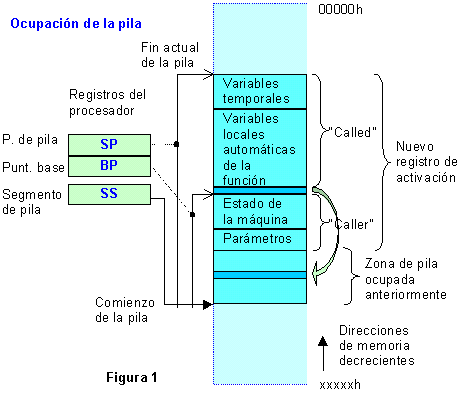
esta razón puntero de pila o SP ("Stack pointer"). Ver figura
![]() .
.
Como veremos a continuación, el marco de pila es un trozo de memoria en este área, que sirve como zona temporal de datos para uso de la función que entra en ejecución. En ella se almacenan los argumentos pasados a la función, sus variables locales y otros datos, como dirección de retorno a la rutina que efectuó la llamada, y estado de los registros en el momento de la invocación.
Nota: en determinadas circunstancias ciertos argumentos pueden pasar a los registros del
procesador, aunque no hay reglas fijas al respecto. Como en todo lo que en C++ se relaciona con el uso de los registros
(register ![]() 4.1.8b), depende
de las circunstancias y del procesador. Ver nota adjunta sobre uso de registros para paso de parámetros en BC++
(
4.1.8b), depende
de las circunstancias y del procesador. Ver nota adjunta sobre uso de registros para paso de parámetros en BC++
(![]() 4.4.6bw1).
4.4.6bw1).
Por supuesto, toda esta información tiene que ser colocada en la pila cada vez que se produce la llamada a una función.
El proceso de construir el marco de pila es lo que se denomina secuencia de llamada. A su vez, cuando termina su
ejecución definitivamente y se devuelve el control a la función que la invocó, la información debe ser sacada de la pila
[5]. El proceso de desmontar el marco de pila se conoce como secuencia de retorno. Ambos procesos
consumen su tiempo, a veces bastante.
Las secuencias de llamada y retorno son realizadas por unos trozos especiales de código denominados prólogo y
epílogo que incluye por su cuenta el compilador junto con cada invocación a función. Aunque en ocasiones esto puede
evitarse; son las denominadas funciones desnudas (![]() 4.4.1b).
4.4.1b).
Recuerde que la secuencia de llamada implica la creación de todas las variables locales de la función (incluyendo los posibles valores que serán devueltos por esta), así como la invocación del constructor-copia para todos los argumentos que no han sido pasados por referencia. Por su parte, en la secuencia de retorno se destruyen todas las variables colocadas en la pila (automáticas) invocando los destructores correspondientes y sus valores se pierden. Recordemos también que los valores estáticos que hubiese en la función tienen espacio de almacenamiento independiente y pueden conservarse.
Conviene resaltar que en el proceso de invocación de una función solo intervienen dos actores: la función que realiza la
invocación ("Caller") y la función que es invocada ("Called"); nosotros las denominamos función invocante
y función invocada (o llamada). Entrambas tienen que repartirse el trabajo de las secuencias de llamada y retorno. El asunto
de "quién" hace "qué" es una de las diferencias entre las distintas convenciones de llamada que hemos
visto en el capítulo anterior (![]() 4.4.6a).
4.4.6a).
Normalmente en C++ es la función invocante la encargada de limpiar la pila y de colocar allí los parámetros. Esto es precisamente lo que hace posible el uso de funciones con número variable de parámetros, ya que en tiempo de compilación, la función invocada no sabe cuantos argumentos recibirá.
 |
§3 El marco de pila
La figura 1 muestra la forma de ocupación de la pila cuando es invocada una nueva función y se crea el correspondiente marco de activación. Observe que la pila crece "hacia abajo", es decir, desde posiciones altas de memoria hacia posiciones más bajas.
La función invocante ("Caller") ocupa una primera zona con copia de los argumentos pasados a la función invocada. Generalmente esta copia se realiza empezando por el último y terminando por el primero (derecha-izquierda). Por ejemplo, en la invocación:
func(a, b, c);
Los argumentos serían pasados en el orden c, b, a. En la figura su colocación sería de abajo a arriba a partir del punto comienzo del nuevo registro de activación.
Nota: el paso de argumentos incluye naturalmente su evaluación previa (recuerde que la sintaxis C/C++ permite utilizar argumentos que son el resultado de una expresión). En lo que respecta al orden en que son pasados, y evaluados, los argumentos, aunque la convención derecha-izquierda es la usual en plataformas Intel, puede variar en otras, por lo que en orden a la portabilidad, y como regla de buena práctica, NO se deben hacerse suposiciones relativas al orden en que serán evaluados los argumentos en las funciones C/C++, y mucho menos, utilizar argumentos cuyo valor dependa de este orden.
A continuación se incluye información sobre el estado de la máquina (valores de los registros). Esta información será utilizada más tarde en el proceso de restaurar la ejecución de la función invocante, de forma que la ejecución siga en la instrucción siguiente a la invocación.
A continuación se sitúa un valor denominado enlace dinámico o de control. Se trata de un puntero que señala al enlace dinámico del registro de activación anterior, que a su vez señala al precedente (así para toda la secuencia de funciones invocadas en un momento dado). Evidentemente la función anterior es la invocante, y en caso de llamadas recursivas (cuando la función se invoca a sí misma), es la activación previa de la misma función. Cuando se inspecciona el estado de la pila con un depurador, la primera función que se encuentra es main; sobre ella, la cadena de funciones invocadas que en ese momento no han tenido retorno.
La dirección del enlace dinámico está contenida en un registro del procesador denominado puntero base BP ("Base
Pointer" ![]() H.3.2). Esta dirección es importante porque en el proceso
de enlazado desaparecen todos los nombres de variables. En el fichero objeto los nombres son sustituidos por las direcciones
de almacenamiento correspondientes, y en el caso de las variables locales dinámicas de las funciones, incluyendo las copias de
los argumentos, estas posiciones están expresadas como desplazamientos en bytes ("Offset") a partir de esta posición
(de ahí el nombre de puntero "base").
H.3.2). Esta dirección es importante porque en el proceso
de enlazado desaparecen todos los nombres de variables. En el fichero objeto los nombres son sustituidos por las direcciones
de almacenamiento correspondientes, y en el caso de las variables locales dinámicas de las funciones, incluyendo las copias de
los argumentos, estas posiciones están expresadas como desplazamientos en bytes ("Offset") a partir de esta posición
(de ahí el nombre de puntero "base").
Por ejemplo: para traer un valor cuyo desplazamiento es 8 de la pila al acumulador (registro AX), al procesador le basta una sola instrucción que en ensamblador puede tener el siguiente aspecto:
...
mov ax,[bp+8]
...
A partir de la posición del enlace dinámico se sitúa un área, rellenada por la función invocada ("Called"),
que contiene todas las variables locales dinámicas de la nueva función (las variables estáticas disponen de su propio espacio
de almacenamiento (![]() 1.3.2). A continuación viene un área denominada de variables temporales que contiene
datos auxiliares del compilador.
1.3.2). A continuación viene un área denominada de variables temporales que contiene
datos auxiliares del compilador.
§4 Sustitución inline
Ocurre con frecuencia, sobre todo en la invocación a funciones pequeñas, que el costo de las secuencias de llamada y retorno
suponen mucho más que el costo de memoria necesario para el cuerpo de la propia función que se invoca. De hecho, C++ dispone
de un especificador de tipo de almacenamiento (que solo es aplicable en la definición de funciones), especialmente concebido
para atender este problema. Se trata de la directiva inline (palabra-clave
![]() 3.2.1).
3.2.1).
Durante la fase de enlazado (![]() 1.4), en cada punto del código donde aparece la invocación a una función, se coloca una
dirección que señala la situación del recurso correspondiente (el código compilado de la misma), pero mediante la directiva
inline, se indica al compilador que en vez del comportamiento habitual, sustituya esta dirección por una
copia del código de la función, lo que se denomina expansión inline.
Resulta evidente que de esta forma se eliminan las secuencias de llamada y retorno, lo que se traduce en una ejecución mucho
más rápida. La contrapartida es que el tamaño del ejecutable resultante es mayor, ya que existe más de una copia de la función;
tantas como sustituciones inline se hayan efectuado. Además, el artificio
presenta algunos inconvenientes que serán comentados a continuación.
1.4), en cada punto del código donde aparece la invocación a una función, se coloca una
dirección que señala la situación del recurso correspondiente (el código compilado de la misma), pero mediante la directiva
inline, se indica al compilador que en vez del comportamiento habitual, sustituya esta dirección por una
copia del código de la función, lo que se denomina expansión inline.
Resulta evidente que de esta forma se eliminan las secuencias de llamada y retorno, lo que se traduce en una ejecución mucho
más rápida. La contrapartida es que el tamaño del ejecutable resultante es mayor, ya que existe más de una copia de la función;
tantas como sustituciones inline se hayan efectuado. Además, el artificio
presenta algunos inconvenientes que serán comentados a continuación.
La declaración de una función como sustituible inline, se realiza en
el sitio de su definición, y tiene la forma general:
inline <tipo_dev> <función> (<parámetros>) {<sentencias>;}
En cualquier sitio donde el código encuentre una invocación a <función>, el compilador sustituirá la invocación por el código contenido en <sentencias>, incluyendo la creación de las variables locales pertinentes. Por ejemplo [2]:
inline float mod (float x, float y) { return sqrt(x*x + y*y); }
inline char* cat_func(void) { return char*; }
Nota: algunos compiladores exigen que la definición inline se realice antes que cualquier invocación a la función.
En ocasiones, el compilador puede hacer caso omiso de la indicación inline; se trata de la misma situación que
con las peticiones register (![]() 4.1.8b), es decir, un mandato no imperativo para el compilador.
4.1.8b), es decir, un mandato no imperativo para el compilador.
![]() En cambio, otras veces el compilador supone una sustitución
inline aunque no se indique explícitamente. Es el caso de las denominadas funciones inline, métodos cuya declaración y
definición se realizan dentro del cuerpo de la clase (
En cambio, otras veces el compilador supone una sustitución
inline aunque no se indique explícitamente. Es el caso de las denominadas funciones inline, métodos cuya declaración y
definición se realizan dentro del cuerpo de la clase (![]() 4.11.2a), o el de determinadas invocaciones a funciones muy pequeñas incluidas en
el cuerpo de otras. En estos casos, el mecanismo de optimización del compilador pueden decidir que su código sea incluido en
el cuerpo de la función invocante [1].
4.11.2a), o el de determinadas invocaciones a funciones muy pequeñas incluidas en
el cuerpo de otras. En estos casos, el mecanismo de optimización del compilador pueden decidir que su código sea incluido en
el cuerpo de la función invocante [1].
En cualquier caso, las correspondientes directivas de compilación, suelen permitir al programador bastante control al
respecto de este tipo de sustituciones, incluyendo posturas intermedias y extremas. Por ejemplo, con objeto de facilitar la
depuración del programa, es posible indicar al compilador que provisionalmente no realice este tipo de sustituciones
![]() . En otros casos, se le puede
ordenar que utilice su criterio para establecer que funciones pequeñas son merecedoras de la sustitución inline
[3]. Finalmente, cabe la opción de dejar la sustitución exclusivamente a criterio del programador
[4].
. En otros casos, se le puede
ordenar que utilice su criterio para establecer que funciones pequeñas son merecedoras de la sustitución inline
[3]. Finalmente, cabe la opción de dejar la sustitución exclusivamente a criterio del programador
[4].
§5 Casos especiales
§5.1 Las funciones con especificador de excepción
(![]() 1.6.4), no son susceptibles de
sustitución inline.
1.6.4), no son susceptibles de
sustitución inline.
§5.2 Evidentemente, estas funciones no son susceptibles de recursión (invocarse a sí mismas) por lo que generalmente el compilador ignora la directiva inline en estos casos.
Nota: los compiladores de Microsoft permiten la substitución inline si la profundidad de recursión puede ser deducida en tiempo de compilación, y siempre que esta profundidad no sobrepase un límite previamente especificado por el programador.
§532 Dependiendo de su estructura interna, algunas funciones no son susceptibles de este tipo de
sustitución. Por ejemplo, en el compilador Borland C++ 5.5 no pueden ser sustituidas inline las funciones que contengan
alguna sentencia de iteración while; do... while y for
(![]() 4.10.3).
Algunos compiladores rehúsan efectuar la substitución si el cuerpo de la
función es muy grande, y tampoco realizan la sustitución en algunos casos en
que la invocación de la función se realiza mediante punteros.
4.10.3).
Algunos compiladores rehúsan efectuar la substitución si el cuerpo de la
función es muy grande, y tampoco realizan la sustitución en algunos casos en
que la invocación de la función se realiza mediante punteros.
§5.4 Las funciones que acepten algún parámetro que sea del tipo "clase con un destructor", no
pueden ser objeto de expansión inline. Sin embargo, esta restricción no es aplicable si se trata de un paso por
referencia. En el primer caso el compilador lanza un mensaje de aviso anunciando que la directiva inline no será tenida
en cuenta.
Ejemplo:
struct est {
...
est(); // Constructor por defecto
~est(); // Destructor
};
inline void f1(est& e) { /* ... */ }
inline void f2(est e) { /* ... */ }
La definición de f1 compilará sin problema, ya que el parámetro es una clase con destructor, pero pasa por
referencia. En la compilación de f2 se producirá un mensaje de aviso: Functions taking class-by-value argument(s)
are not expanded inline in function f2(est).
§5.5 Cualquier función que devuelva una clase con destructor no puede ser objeto de expansión
inline, cuando dentro de la expresión de retorno puedan existir variables u objetos temporales que necesiten ser
destruidos.
Ejemplos:
struct est {
est(); // constructor por defecto
~est(); // destructor
};
inline est f1() { // Ok: puede ser sustituida inline
return est();
}
inline est f2() { // Aviso: No sustituible inline
est e2;
return est();
}
Esta función no puede ser sustituida, porque el objeto e2 necesita ser destruido, en consecuencia, se genera un
aviso del compilador: Functions containing some return statements are not expanded inline in function f2().
En esta otra:
inline est f3() { // Aviso: No sustituible inline
return ( est(), est() );
}
se genera un mensaje de aviso análogo al anterior. Tampoco puede ser sustituida porque el valor devuelto contiene objetos temporales.
§6 Criterio de uso
En aras a la velocidad de ejecución, es preferible evitar en lo posible la utilización de funciones pequeñas, especialmente
en bucles que se repiten un gran número de veces. En caso de tener que utilizarlas es preferible acudir a la sustitución
inline. También son buenas candidatas a esta sustitución las funciones-operador
(![]() 4.9.18).
4.9.18).
Aunque lo anterior supone ir contra dos reglas generales de la buena programación: la reutilización del código, y la compartimentación de datos y procedimientos. En este sentido, la sustitución inline supone una situación intermedia; sin las desventajas de la llamada y retorno a función, pero (desde el punto de vista del programador), con las ventajas de la utilización de funciones en cuanto suponen el encapsulamiento del código en un único sitio. La opción a elegir en cada caso (función tradicional o sustitución inline), es como siempre una cuestión definir prioridades entre el cronómetro y el tamaño del código resultante.
Nota: a menos que el compilador permita otro tipo de medida al respecto
![]() , cuando sea importante reducir el tamaño del código,
debe recordar definir las funciones miembro fuera del cuerpo de la definición
de la clase, para evitar la sustitución inline antes aludida, que en estos casos es realizada automáticamente por el
compilador.
, cuando sea importante reducir el tamaño del código,
debe recordar definir las funciones miembro fuera del cuerpo de la definición
de la clase, para evitar la sustitución inline antes aludida, que en estos casos es realizada automáticamente por el
compilador.
Cuando se trata de optimizar funciones que no son escritas por el programador. Por ejemplo, cuando se utilizan los
recursos de la Librería Estándar, es conveniente recordar que los modernos compiladores traen algunas de estas librerías en
dos formatos: como funciones y como macros, y el programador puede optar entre una y otra forma §8
![]() .
.
§7 Depuración de funciones inline
Puesto que en estas sustituciones el compilador reemplaza la llamada a función por "su versión" del código de la
misma, aún cuando en la compilación se hayan incluido las opciones de depuración
(![]() 1.4), no existe
una correspondencia entre las líneas de código del fuente y el ejecutable, lo que hace difícil la depuración de este tipo de
funciones. Para evitar estas dificultades, los compiladores ofrecen una serie de opciones con las que se pueden controlar
diversos aspectos de la construcción del ejecutable en las versiones de depuración.
1.4), no existe
una correspondencia entre las líneas de código del fuente y el ejecutable, lo que hace difícil la depuración de este tipo de
funciones. Para evitar estas dificultades, los compiladores ofrecen una serie de opciones con las que se pueden controlar
diversos aspectos de la construcción del ejecutable en las versiones de depuración.
Nota: para facilitar la depuración de estas funciones, algunos compiladores ignoran la directiva inline cuando se compila en modo "debug".
En el caso concreto del compilador BC++ se ofrece el siguiente abanico de posibilidades de compilación
(![]() 1.4.3):
1.4.3):
- -v Opciones de depuración ON; expansión inline OFF
- -v- Opciones de depuración OFF; expansión inline ON
- -vi Expansión inline ON
- -vi- Expansión inline OFF (las funciones inline son expendidas fuera de línea)
El compilador GNU Cpp ofrece la opción -fno-default-inline, que hace que las funciones miembro no sean consideradas inline por el mero hecho de haber sido declaradas dentro del cuerpo de la clase.
§8 Macro-sustitución
La macro-sustitución, a la que hemos hecho referencia en el párrafo anterior, es una técnica similar a la
sustitución inline que ha sido ampliamente utilizada (como herencia del C), pero que no debe ser confundida con esta
última. Su utilización ha caído bastante en desuso y está desaconsejado, dado que presenta algunos inconvenientes que se
detallan en el capítulo correspondiente (#define ![]() 4.9.10b). Se basa en la utilización del preprocesador C/C++ para simular la invocación de funciones
que no son tales. Ejemplo:
4.9.10b). Se basa en la utilización del preprocesador C/C++ para simular la invocación de funciones
que no son tales. Ejemplo:
#define abs (x) (x < 0? (-x) > x)
...
func f(x) {
int y = abs(x);
...
}
Es frecuente que algunas rutinas de librería, que adoptan la forma de funciones pequeñas, puedan venir en formas dos
formatos: como función y como macro, pudiendo optar el programador entre una y otra forma. Esta última (las
macros) viene a ser el equivalente de la sustitución inline para tales funciones de librería. Ver "Funciones y
macros" (![]() 5.1) para una clarificación sobre esta cuestión.
5.1) para una clarificación sobre esta cuestión.
[1] En estas circunstancias, puede ocurrir que todas las invocaciones a una función muy simple (no declarada explícitamente como inline), hayan sido sustituidas por el código correspondiente dentro de la función invocante, con lo que formalmente no existe código binario que corresponda como tal a la función sustituida.
[2] La función sqrt no está en el estándar ANSI C++; debería ser sustituida por pow que sí está en el estándar.
[3] Por ejemplo, la directiva -finline-functions deja al compilador GNU Cpp la decisión de que funciones son suficientemente simples para merecer esta sustitución.
[4] A partir de la versión 6 de Visual C++, Microsoft ha incorporado la directiva __forceinline (es además una palabra-clave en VC++), que evita el análisis costo/velocidad por parte del compilador en el momento de decidir si efectivamente se realizará una sustitución inline, dejando el asunto enteramente a criterio del programador. Por supuesto es una opción específica de "Visual", que debe evitarse (como cualquier otra particularidad), si queremos construir código portable.
[5] Recordemos la función llamada puede realizar a su vez invocaciones a otras funciones (incluso a si misma) en un proceso de profundidad indefinida. En cada una de estas invocaciones la función cesa su actividad; pasa el control de ejecución a la nueva función, y lo retoma cuando esta finaliza. La finalización definitiva ocurre cuando devuelve a su vez el control a la función que la invocó.
[6] Sin embargo nada impide que lo que se copia sea un puntero al dato, en lugar del dato propiamente dicho.