5.2 Internacionalización
"locales and facets as one friend of mine says: another obscure and esoteric C++ topic that nobody is interested in". Jack W. Reeves "Using IOStreams - locales and facets" C/C++ Users Journal. Mayo 2001.
§1 Introducción
Cuando los sistemas informáticos dejaron de ser exclusivos de un pequeño círculo de iniciados, se hizo evidente que la interacción con sus usuarios debía efectuarse siguiendo las convenciones culturales de cada individuo. De estas, la principal aunque no única, es el idioma y su particular juego de caracteres [1]. Aunque existen otras no menos importantes, como los formatos de fechas; números decimales; monedas, etc. Estos conjuntos de costumbres específicas de cada cultura o área geográfica particular se denominan localismos.
Tradicionalmente, desarrollar aplicaciones para diversos mercados presentaba problemas de difícil solución. Por ejemplo: Inglés-americano; Inglés del Reino Unido; Francés; Español; Alemán, Etc. Cada cual utilizaba diversas técnicas para intentar mantener todas estas versiones con un mínimo de esfuerzo. Una de ellas consistía en mantener todos los mensajes y avisos textuales (ayudas, Etc.) en ficheros separados del fuente, de forma que (con ayuda de traductores profesionales) fuese fácil mantener versiones en los diversos lenguajes. Estas versiones eran compiladas según el caso mediante directivas condicionales de preproceso. Sin embargo, esto no era siempre factible, en especial en las rutinas de E/S formateadas. Las pantallas ("Screens") de entrada/salida de datos y los listados de salida debían ser mantenidos en el fuente en diversas versiones que eran igualmente mantenidas mediante complicadas sentencias condicionales de preproceso.
El hecho de construir un software que pueda responder a convenciones culturales distintas (aspecto este cada día más importante en la aldea global) se conoce como internacionalización, abreviadamente I18N [1a]. Desde luego siempre puede rehacerse completamente un fuente desarrollado para un ambiente cultural determinado para adaptarlo a otro. Por ejemplo del español al finlandés; pero si queremos hacerlo con un máximo de economía de recursos, la internacionalización de cualquier software que daba ser portado a diversas culturas debe estar considerada como un principio de diseño.
En las aplicaciones C/C++ la I18N se basa en dos estrategias complementarias:
-
El programador no debe incluir mensajes en el código, ni ningún otro texto que deba ser mostrado al usuario. Esta información se identifica en el fuente mediante constantes numéricas. Los textos correspondientes ("Captions") se almacenan en ficheros externos, de forma que puedan ser traducidos sin necesidad de recompilar el programa. Estos ficheros se conocen genéricamente como tablas de cadenas ("Stringtables"). Las herramientas para su manejo suelen ser dependientes de la plataforma.
-
El programador tampoco deberá efectuar ninguna suposición específica sobre formatos numéricos, de moneda, de fechas, de secuencias de ordenación de caracteres, Etc. Esta información es almacenada en tablas específicas que son consultadas automáticamente por las rutinas que lo requieren, adaptando su comportamiento al formato y convenciones definidos en ellas. Estas tablas, cuyo contenido es distinto para cada entorno cultural se denominan locales.
Una vez que el software está internacionalizado, el proceso de instanciarlo para obtener una versión adaptada a una cultura específica se denomina localización. Este proceso implica la adopción de medidas tanto por parte del desarrollador de la aplicación como de los constructores y administradores de sistemas operativos y de los propios usuarios. El desarrollador debe desde luego traducir los mensajes de la aplicación. Por su parte el fabricante y administrador del SO deben incluir en el entorno de ejecución una serie de facilidades específicas. Estas facilidades se basan en la adaptación de una serie de tablas (locales) que contienen datos relevantes de cada localismo particular [2]. Finalmente, el usuario interviene seleccionando las convenciones locales que prefiere dentro de las disponibles en su entorno de ejecución.
En esta sección describiremos las ayudas que ofrece la Librería Estándar C++ para facilitar la internacionalización de los programas, empezando por describir cuales son las diferencias entre los diversos localismos.
§2 Diferencias locales básicas
Son muchas las diferencias que pueden presentarse entre los diversos localismos que existen en el mundo. Unas podrían considerarse básicas, otras no son fundamentales, pueden considerarse más bien de tipo cosmético. Por ejemplo, el manejo de teclados internacionales o el tipo de fuente para la escritura. Entre las primeras están las siguientes:
-
Lenguaje

-
Representación numérica
-
Moneda
-
Hora y fecha
-
Secuencia de ordenación
§2.1 Localismos del lenguaje:
Comprende el lenguaje natural utilizado (español, inglés, francés griego, Etc.) y el juego de caracteres que constituye su alfabeto, incluyendo los signos de puntuación.
Ejemplo:
| Inglés americano: | a-z; A-Z; signos de puntuación |
| Alemán | a-z; A-Z; signos de puntuación; äöü ÄÖÜ ß |
| Griego: | a-w; A-W; signos de puntuación |
§2.2 Localismos numéricos
La representación de las cantidades numéricas depende de costumbres locales que varían de país en país. La más conocida es quizás la distinta forma de representar la fracción decimal de los números fraccionarios. En inglés americano se utiliza un punto . para separar la parte entera de la decimal, mientras que en la mayor parte de Europa se utiliza la coma , para este mismo fin [3]. Recíprocamente, en USA se utiliza la coma para separar los grupos de tres cifras de las magnitudes grandes (símbolo de separación de miles) y en Europa se utiliza el punto. Incluso la forma de agrupar las cifras es distinta en las diversas culturas.
Ejemplo:
| USA: | 1,000,000,55 |
| España: | 1.000.000,55 |
| Nepal: | 10,00,000.55 |
A título de ejemplo, incluimos los aspectos locales numéricos que pueden ser configurados por el usuario en Windows 98:
Símbolo decimal
Número de cifras decimales por defecto
Símbolo de separación de miles
Número de dígitos en grupo
Símbolo de número negativo
Formato de números negativos
Mostrar ceros a la izquierda
Sistema métrico utilizado
§2.3 Localismos de moneda
* Como puede verse, la redacción original de este apartado corresponde a algún momento anterior a la adopción de la moneda única en la U.E (Euro €) sin embargo, la he mantenido porque la idea permanece y la exposición sigue siendo didáctica.
Además de que el sistema monetario es distinto en los diversos países del mundo, también existen importantes diferencias en la forma en que son representadas las magnitudes monetarias, incluyendo el símbolo de la moneda y la representación de los valores negativos. Por ejemplo, existen dos formas de representar la misma cantidad de dólares USA:
| USA: | $24.99 US |
| Resto de países del mundo: | 24.99 USD |
La posición del símbolo monetario puede estar al principio, al final, o incluso en medio del valor numérico:
El formato de las cantidades negativas también varía:
| Austria: | ÖS 13,10 -ÖS 13,10 |
| Alemania [4]: | 13,50 DM -13,50 DM |
| Suiza: | SFr.13.50 SFr.-13.50 |
| Hong Kong: | HK$13.50 (HK$13.50) |
Como ejemplo, señalemos que Windows 98 permite especificar los siguientes localismos monetarios:
Símbolo de moneda
Posición del símbolo respecto del número.
Símbolo que separa la parte decimal.
Número de cifras decimales por defecto.
Símbolo de separación de miles.
Número de dígitos en grupo.
§2.4 Localismos de fecha y hora
Las formas de representación de fecha y hora varían grandemente entre los diversos grupos culturales. Algunos países o grupos utilizan un sistema horario de 24 horas, mientras otros utilizan el de 12. Por supuesto en cada lengua varían las abreviaturas utilizadas para meses y días de la semana, así como los símbolos utilizados para separarlas.
Aunque la mayoría de países del mundo "Occidental" utiliza un sistema de tiempo basado en el calendario Gregoriano, existen otros basados igualmente en razones históricas. Por ejemplo, el calendario oficial Japonés se basa en el año de reinado del Emperador, mientras que la era de los Mahometanos cuenta desde el 15 de Julio del año 622 (fecha Gregoriana) en que Mahoma huyó de la Meca a Medina.
A continuación se muestran diversos ejemplos de representación de la misma fecha en diferentes países.
| USA: | 10/29/96 | Tuesday, October 29, 1996 |
| Hungría: | 1996. 10. 29. | 1996. oktöber 29. |
| Italia: | 29/10/96 | martedì 29 ottobre 1996 |
| Grecia: | 29/10/1996 | Trith, 29 Oktwbriou 1996 |
| Alemania: | 29.10.96 | Dienstag, 29. Oktober 1996 |
| España: | 29-10-96 | Martes 29 de Octubre de 1996 |
Ejemplos de representación de la misma hora:
| USA: | 4:55 pm |
| Alemania: | 13:55 Uhr |
| España: | 4.55 pm. |
Ejemplos de representación digital de la misma hora:
| USA: | 11:45:15 |
| Grecia: | 11:13:45 mm |
§2.5 Localismos de ordenación
Los diversos lenguajes tienen distintos criterios en lo referente a la ordenación de sus caracteres. A efectos de la ordenación alfabética de sus cadenas alfanuméricas (por ejemplo la que establece el orden de aparición de sus palabras en un diccionario) existe una secuencia de caracteres que puede considerarse el orden "oficial" en cada lengua. Esta secuencia ordenada es lo que se denomina secuencia de ordenación ("collating sequence"), y es la que se utiliza como base para cualquier ordenación alfabética.
Como ejemplo se muestra una misma lista de palabras ordenada según dos secuencias de ordenación distintas, la del código
ASCII (![]() 2.2.1a)
y la de la Lengua Alemana:
2.2.1a)
y la de la Lengua Alemana:
|
ASCII |
Alemán |
||
| Airplane | Airplane | ||
| Zebra | ähnlich | ||
| bird | bird | ||
| car | car | ||
| ähnlich | Zebra |
La secuencia de ordenación ASCII está basada en los valores numéricos de sus bytes correspondientes, que no se corresponde con las reglas de la lengua Inglesa (la que puede encontrarse en un diccionario de inglés). En esta lengua la a minúscula se considera después de la A mayúscula y antes que la B, mientras que la secuencia ASCII las mayúsculas preceden a todas las minúsculas.
En el alfabeto Alemán la ä (umlaut) está situada antes que la b, mientras que en el código ASCII se sitúa después de todas las letras (en la zona de caracteres extendidos).
Además de especificar el orden de cada carácter, algunos lenguajes consideran ciertos grupos de caracteres como uno solo, lo que también afecta la ordenación. El siguiente ejemplo muestra una serie de palabras ordenadas según el criterio ASCII y el del Español:
|
ASCII |
Español |
||
| chaleco | cuna | ||
| cuna | chaleco | ||
| día | día | ||
| llave | loro | ||
| loro | llave | ||
| maíz | maíz |
En el alfabeto Español los dígrafos ll y Ll representan las dos versiones (minúscula y mayúscula) de una sola letra de nombre "Elle", situada entre la L y la M. También el dígrafo ch es tratado en Español como una sola letra, de nombre "Che" y situada entre la C y la D. Estos casos en que dos grafos, que en otras circunstancias pueden existir aislados, son agrupados para formar un solo carácter, se denominan pares de caracteres dos-a-uno [12].
En otros casos un solo carácter es considerado como si fuesen dos. Por ejemplo, el carácter del aleman clásico ß (denominado sharp), es equivalente al dígrafo ss en el alemán moderno. Este tratamiento origina una diferencia en la ordenación como se muestra en la siguiente lista:
|
ASCII |
Alemán |
||
| Rosselenker | Rosselenker | ||
| Rostbratwurst | Roßhaar | ||
| Roßhaar | Rostbratwurst | ||
| strasse | straße | ||
| straße | strasse |
§3 Localismos en C
Tanto los programadores como los fabricantes de compiladores fueron rápidamente conscientes que sería de gran ayuda disponer en el propio lenguaje de herramientas específicas que ayudaran a la internacionalización. La idea es que la información correspondiente a las diferencias locales fuese de algún modo accesible al programa, de forma que pudiera ser utilizada por las rutinas afectadas (principalmente de E/S) de la forma más automática posible. En respuesta a esta necesidad, el consorcio X/Open [8] estandarizó una serie de servicios que proporcionan un soporte de estas características en el lenguaje C. Estos servicios son conocidos como NLS ("Native Languaje Support") o XPG4.
De acuerdo con el XPG4 los localismos C están agrupados según su contenido en varias categorías, identificadas internamente
mediante seis constantes manifiestas (![]() 1.4.1a), que coinciden aproximadamente con las que hemos enunciado
1.4.1a), que coinciden aproximadamente con las que hemos enunciado
![]() :
:
| LC_NUMERIC | Reglas y símbolos para localismos numéricos. |
| LC_TIME | Detalles y reglas para fecha y hora |
| LC_MONETARY | Reglas y símbolos para localismos de moneda. |
| LC_CTYPE | Reglas de clasificación de caracteres y conversión mayúsculas/minúsculas |
| LC_COLLATE | Reglas de ordenación |
| LC_MESSAGES | Formato y valor de los mensajes |
![]() Cada
localismo representa un conjunto de reglas relativas a un aspecto cultural
específico. Por supuesto, para cada entorno cultural hay que definir
seis conjuntos de reglas (uno para cada categoría), de forma que por ejemplo,
para Francia hay que definir el conjunto de reglas para representar los
números; para fecha y hora; para cantidades monetarias, etc. El proceso
debe repetirse para cada país o entorno cultural. Es posible
incluso concebir un entorno que fuese mezcla de otros. Por ejemplo: podría definirse un localismo para el entorno
canadiense francófono tomando categorías del localismo Inglés-USA y del Francés de Francia.
Cada
localismo representa un conjunto de reglas relativas a un aspecto cultural
específico. Por supuesto, para cada entorno cultural hay que definir
seis conjuntos de reglas (uno para cada categoría), de forma que por ejemplo,
para Francia hay que definir el conjunto de reglas para representar los
números; para fecha y hora; para cantidades monetarias, etc. El proceso
debe repetirse para cada país o entorno cultural. Es posible
incluso concebir un entorno que fuese mezcla de otros. Por ejemplo: podría definirse un localismo para el entorno
canadiense francófono tomando categorías del localismo Inglés-USA y del Francés de Francia.
Las reglas que definen los localismos se materializan un
conjunto de ficheros mantenidos por el Sistema que son identificados por un nombre. Su
número y denominación dependen del Sistema Operativo y no están
estandarizadas (dentro de la iniciativa PSOX, el IEEE ha normalizado algunas
denominaciones para entornos UNIX). A título de ejemplo, en la página adjunta se muestran los
que están disponibles en los sistemas de Microsoft (![]() 5.2.4). A su vez, dentro del programa
los localismos están representados por ciertas estructuras globales (en el sentido C del término),
cuyos miembros contienen los datos pertinentes, y que son consultadas automáticamente por las funciones de librería que
dependen de localismos. Por ejemplo: la estructura denominada lconv,
almacena información sobre localismos numéricos y monetarios.
5.2.4). A su vez, dentro del programa
los localismos están representados por ciertas estructuras globales (en el sentido C del término),
cuyos miembros contienen los datos pertinentes, y que son consultadas automáticamente por las funciones de librería que
dependen de localismos. Por ejemplo: la estructura denominada lconv,
almacena información sobre localismos numéricos y monetarios.
Para el manejo de estas estructuras se han provisto dos
nuevas funciones: localeconv() para consulta (![]() Ejemplo-1), y setlocale() para cargar los ficheros externos
(ejemplo
Ejemplo-1), y setlocale() para cargar los ficheros externos
(ejemplo ![]() ).
Es corriente referirse colectivamente a estos conjuntos de
valores y reglas como un locale. Inicialmente el compilador proporciona unos valores por
defecto a estos locales, pero se pueden cargar otros desde el
fichero externo correspondiente mediante setlocale. A partir de su invocación, las reglas y criterios
del nuevo locale quedan a disposición de las funciones que los necesiten.
).
Es corriente referirse colectivamente a estos conjuntos de
valores y reglas como un locale. Inicialmente el compilador proporciona unos valores por
defecto a estos locales, pero se pueden cargar otros desde el
fichero externo correspondiente mediante setlocale. A partir de su invocación, las reglas y criterios
del nuevo locale quedan a disposición de las funciones que los necesiten.
La definición y reglas de uso de setlocale pueden ser consultadas en el manual de su compilador, pero adelantaremos aquí que no solo permite establecer nuevos valores para los localismos, también consultar los valores actuales [10]. Su definición está en <locale.h> o <clocale>, y existe en dos versiones: una para caracteres normales y otra para caracteres anchos. La primera responde a la declaración:
char* setlocale(int category, const char* locale);
La función devuelve un puntero a carácter que
señala el principio de una cadena identificativa del localismo. El argumento category
es una constante manifiesta que permite definir que categoría se
fija/consulta. Puede ser cualquiera de las señaladas en la tabla
anterior ![]() o LC_ALL que afecta a todas las categorías. El argumento locale es un puntero a cadena de caracteres
que identifica el locale que se desea cargar. Este argumento acepta diversas formas:
o LC_ALL que afecta a todas las categorías. El argumento locale es un puntero a cadena de caracteres
que identifica el locale que se desea cargar. Este argumento acepta diversas formas:
| "lang[_country[.code_page]]" | Establece el locale que se cargará |
| ".code_page" | Establece la página de códigos
que se debe cargar ( |
| "" | Establece el localismo establecido por defecto para el SO. |
| NULL | Modo consulta: devuelve el localismo actualmente en uso sin realizar ningún cambio. |
§3.1 Localismo por defecto
El ANSI C establece un localismo estándar de nombre "C", que
corresponde con el entorno en que se ejecutaban tradicionalmente los programas C. Naturalmente este entorno es el de USA,
su juego de caracteres es el US-ASCII. Cuando se inicia un programa C, sus rutinas
de inicio (![]() 1.5) ejecutan automáticamente una invocación al Sistema equivalente a:
1.5) ejecutan automáticamente una invocación al Sistema equivalente a:
setlocale(LC_ALL, "C");
que establece el entorno de funcionamiento al localismo por defecto. El resultado es que incluso cuando no se utiliza explícitamente el mecanismo de locales, en realidad se está utilizando la configuración estándar ANSI "C". Si nuestros programas pueden sobrevivir correctamente en el ambiente Inglés-USA, no es necesario hacer absolutamente nada respecto a este asunto de la internacionalización.
§3.2 Localismo nativo
En ocasiones el programador no impone un localismo específico, decidiendo que sea el usuario el que establezca el que desea. En estos casos puede utilizarse al principio del programa una invocación en la forma:
setlocale(LC_ALL, "");
Esta llamada establece el localismo establecido por defecto en el SO.
Nota: en estos casos, el usuario debe establecer sus preferencias locales antes de arrancar la aplicación. La forma de hacerlo depende del Sistema anfitrión. Por ejemplo, en los Sistemas Unix se establece una variable de entorno como LANG. En los Sistemas Windows 98 según se ha señalado en la nota [2].
§3.3 Funciones dependientes del localismo
De lo dicho anteriormente se desprende que un número de funciones de la Librería Estándar C adaptan automáticamente ciertos detalles de su funcionamiento de los valores del locale. Este tipo de código se denomina adaptativo y a título de ejemplo podemos citar las siguientes funciones:
| Función | Tipo de información que maneja |
| isalpha(), isupper(), isdigit(), ... | Información sobre caracteres. |
| tolower(), toupper() | Conversiones mayúsculas/minúsculas |
| atof(), atoi(), atol() | Convertir cadenas de caracteres a valores numéricos |
| strftime(), ... | Fecha y hora |
| strfmon() | Monetaria |
| printf(), scanf(), ... | Análisis y formateos numéricos |
| strcoll(), wcscoll(), ... | Ordenación y comparación alfabéticas de cadenas |
| mblen(), mbtowc(), wctomb(), ... | Caracteres multibyte. |
| catopen(), catgets(), catclose() | Mensajes textuales. |
El ejemplo que sigue ilustra el principio de funcionamiento y como el entorno local afecta
el comportamiento de la función printf().
#include <locale.h> // compilar como programa C #include <stdio.h>
float fl = 1.2345F;
char* loc;
int main() { // =================
loc = setlocale(LC_ALL, NULL); // modo consulta
printf("locale actual: %s\n", loc);
printf("Valor de fl: %f\n", fl);
loc = setlocale(LC_ALL, ""); // localismo nativo
printf("locale actual:\n%s\n", loc);
printf("Valor de fl: %f\n", fl);
loc = setlocale(LC_ALL, "german"); // localismo específico (alemán)
printf("locale actual:\n%s\n", loc);
printf("Valor de fl: %f\n", fl);
return 0;
}
Salida:
locale actual: C
Valor de fl: 1.234500
locale actual:
LC_MONETARY=Spanish_Spain.850
LC_TIME=Spanish_Spain.850
LC_NUMERIC=Spanish_Spain.850
LC_COLLATE=Spanish_Spain.850
LC_CTYPE=Spanish_Spain.850
Valor de fl: 1,234500
locale actual:
LC_MONETARY=German_Germany.850
LC_TIME=German_Germany.850
LC_NUMERIC=German_Germany.850
LC_COLLATE=German_Germany.850
LC_CTYPE=German_Germany.850
Valor de fl: 1,234500
Comentario:
La salida corresponde a una compilación C con Borland C++ 5.5 ejecutada bajo Windows-98. Como configuración regional el Sistema tiene seleccionado "Español (España)".
Observe como el cambio de locale del ambiente USA al español, o alemán, modifica la representación del punto decimal del float.
§3.4 Problemas de los locales C
El punto importante a recordar aquí, es que los locales C son estructuras globales de las que solo existe una versión en un momento dado. Esta circunstancia hace que solo puede existir un localismo para toda la aplicación, y sea difícil atender simultáneamente distintos localismos. Sin embargo, esta necesidad se presenta frecuentemente en aplicaciones de compañías que operan en diversos entornos culturales. Supongamos por ejemplo, que una multinacional USA opera en España. Las bases de datos, por ejemplo listas de precios, han sido desarrolladas en USA y son globales para toda la organización. Aunque contienen una columna correspondiente a los precios en Dólares USA y otra en Euros, son mantenidas por la central en USA según las normas ANSI "C". Las listas de precios son actualizadas regularmente por la delegación Española (digamos vía Internet), pero naturalmente, el proceso de facturación debe utilizar las convenciones culturales Españolas.
En estas condiciones, el programa de facturación, que debe leer datos según una norma y escribirlos según otra, respondería al siguiente esquema:
while ( true ) { // procesar la factura en Español
...
setlocale(LC_ALL, "english-us");
fscanf(...); // leer tabla de precios USA ...
setlocale(LC_ALL,"spanish");
fprintf(...); // escribir datos de factura ...
}
El principal problema es que los ficheros english-us y spanish son externos al programa, y las operaciones de carga y posterior actualización de las estructuras globales son procesos costosos que ralentizan la ejecución.
§4 Localismos en C++
"If you thought locales were an esoteric aspect of the Standard C library, wait till you see what the draft C++ Standard has done with locale objects". P.J. Plauger: "Introduction to Locales". C/C++ Users Journal. Octubre 1997.
Como veremos inmediatamente, el esquema C de tratamiento de localismos se mantiene en C++ por compatibilidad (las definiciones correspondientes al fichero clásico <locale.h> han sido trasladadas a <clocale>), pero este lenguaje ofrece un tratamiento particular y específico del problema de la internacionalización, mucho más potente y versátil que su contrapartida C, pero también mucho más complejo y sofisticado [9].
Los localismos C++ ofrecen servicios similares a los de C, aunque los mecanismos involucrados difieren. Por ejemplo, los localismos C son recursos globales, y hemos señalado que solo puede existir un localismo para toda la aplicación; en consecuencia, es difícil conseguir que pueda atender simultáneamente a diversos localismos. En cambio, como el localismo C++ está definido en una clase, pueden instanciarse diversos objetos que pueden conexistir y cada uno puede servir a una convención cultural específica.
Nota: En palabras del mencionado P.J. Plauger [11]: "Un mecanismo para manipulación de localismos imaginativo y extremadamente ambicioso". A continuación añade: "(el mecanismo) estira el lenguaje C++ hasta el límite mediante la utilización de características votadas en el borrador (del Estándar) que solo recientemente han sido añadidas a los compiladores comerciales. Realmente no puedo imaginar un programa tan sofisticado en su uso de localismos que pueda encontrar alguna razón para hacer deseable la parafernalia adoptada".
§4.1 Facetas
Como no podía ser menos, la información y su manipulación, que en el caso de C está contenida en estructuras y en
funciones globales, ha sido sustituida en C++ por unas clases denominadas facetas ("Facets")
[7] que derivan de una superclase facet. Un objeto facet puede contener prácticamente
cualquier aspecto de internacionalización. Por ejemplo, el formato y símbolo de valores monetarios; los de fecha, Etc. La LE
proporciona un par de docenas de estas clases (![]() 5.2.1) que proporcionan servicios similares a los proporcionados por la
librería Estándar C. Un facet encapsula la información local que en C está englobada en una categoría
CL_...,
aunque de forma más especializada. Por ejemplo, la funcionalidad contenida en la categoría LC_NUMERIC está
dispersa en 4 facetas:
5.2.1) que proporcionan servicios similares a los proporcionados por la
librería Estándar C. Un facet encapsula la información local que en C está englobada en una categoría
CL_...,
aunque de forma más especializada. Por ejemplo, la funcionalidad contenida en la categoría LC_NUMERIC está
dispersa en 4 facetas:
template <class charT> class numpunct;
template <class charT> class numpunct_byname;
template <class charT, class InputIterator > class num_get;
template <class charT, class OutputIterator> class num_put;
De estas clases existen espacializaciones para los tipos char y wchar_t, de forma que existen las siguientes:
|
numpunct<char> numpunct<wchar_t> numpunct_byname<char> numpunct_byname<wchar_t> |
num_get<char> num_get<wchar_t> num_put<char> num_put<wchar_t> |
Las facetas C++ son clases muy flexibles (en realidad clases genéricas); también
pueden ser definidas por el usuario o ser adquirida a terceros en forma de
librería. Lo mismo que ocurría con los localismos C, las facet
también se clasifican en seis categorías, y aunque en este caso los nombres
no corresponden a constantes manifiestas, también corresponden a constantes enteras que rememoran muy de cerca los nombres
utilizados en C ![]() :
numeric; time; monetary; ctype; collate y message.
:
numeric; time; monetary; ctype; collate y message.
§4.2 locales
Debemos recordar que los
diseñadores del lenguaje han realizado un considerable esfuerzo para mantener
compatibilidad hacia atrás con el código tradicional C (![]() 1.2) y el mecanismo de internacionalización no es una
excepción. En consecuencia, los programadores C++ que deseen seguir utilizando el estilo
C clásico pueden seguir haciéndolo. Además, como en la mayoría de aplicaciones es suficiente un
solo localismo, para evitar que en cada caso haya que especificar cual utilizar,
el Estándar C++ ha definido una instancia global de la clase locale que
mimetiza el comportamiento del C con sus estructuras globales.
1.2) y el mecanismo de internacionalización no es una
excepción. En consecuencia, los programadores C++ que deseen seguir utilizando el estilo
C clásico pueden seguir haciéndolo. Además, como en la mayoría de aplicaciones es suficiente un
solo localismo, para evitar que en cada caso haya que especificar cual utilizar,
el Estándar C++ ha definido una instancia global de la clase locale que
mimetiza el comportamiento del C con sus estructuras globales.
El valor de este locale global se establece mediante el método estático std:locale::global() y cuando se instancia la clase std::locale utilizando su constructor por defecto, el objeto se inicializa con el valor del localismo global de ese momento. En consecuencia, si un algoritmo necesita un localismo específico, puede hacerlo mediante el argumento adecuado del constructor; en caso contrario, se utiliza automáticamente el localismo global.
Nota: a efectos de facilitar esta compatibilidad, salvo medidas en contrario, el locale
global afecta a la totalidad del programa. Por ejemplo, los
objetos iostream (![]() 5.3.1) utilizan este objeto para sus formateos en caso que no se les inserte ningún otro objeto
local. Es posible obtener una copia del locale global mediante un método de la clase: locale::global
(
5.3.1) utilizan este objeto para sus formateos en caso que no se les inserte ningún otro objeto
local. Es posible obtener una copia del locale global mediante un método de la clase: locale::global
(![]() 5.2.2), y se dispone incluso de un método
locale::classic (
5.2.2), y se dispone incluso de un método
locale::classic (![]() 5.2.2) que devuelve la referencia a un objeto que representa el equivalente C++ del
entorno estándar "C"
5.2.2) que devuelve la referencia a un objeto que representa el equivalente C++ del
entorno estándar "C"
![]() .
.
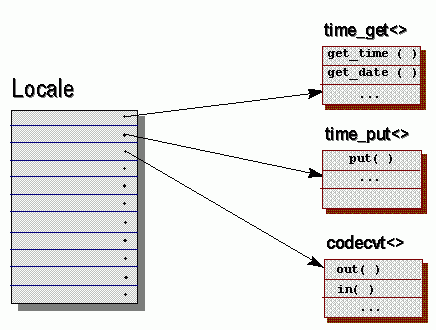 |
La clase locale viene a ser una especie de contenedor de estas facet.
según el esquema que se muestra en la figura adjunta [6];
aunque en realidad su propósito es doble: de una parte, sirve como
interfaz unificada de estas facet. De otra, es una colección clasificada
de facet en ocho categorías. Para ello los objetos de la clase locale
tienen una serie miembros estáticos (![]() 4.11.7) denominados genéricamente category que en realidad son constantes enteras con los
siguientes nombres: none, collate, ctype, monetary, numeric, time, messages
y all. Sus valores dependen del compilador, pero están definidos de forma que:
4.11.7) denominados genéricamente category que en realidad son constantes enteras con los
siguientes nombres: none, collate, ctype, monetary, numeric, time, messages
y all. Sus valores dependen del compilador, pero están definidos de forma que:
none = 0;
all = collate | ctype | monetary | numeric | time | messages;
Además de estos miembros, la clase locale contiene dos subclases contenidas en ella: facet e id.
Las facetas de un localismo (locale) son accedidas a través de dos funciones genéricas: use_facet<>() y has_facet<>(). Tales funciones no son métodos de la clase locale, aunque aceptan un locale como argumento. Resulta posible determinar si una facet particular está contenida en un locale utilizando la función has_facet, y en su caso puede obtenerse una referencia a dicha facet, mediante la función use_facet.
§4.3 Webografía
Respecto al asunto, quizás la mejor referencia ses un artículo explicativo
del responsable de su inclusón el en Estándar: "The Standard C++ Locale"
de Nathan C. Myers  www.cantrip.org.
www.cantrip.org.
[1] Al tratar de los tipos
carácter (![]() 2.2.1a),
señalamos los problemas que aparecieron al intentar internacionalizar un
estándar que inicialmente solo estaba pensado para escribir en el Inglés-americano.
2.2.1a),
señalamos los problemas que aparecieron al intentar internacionalizar un
estándar que inicialmente solo estaba pensado para escribir en el Inglés-americano.
[1a] "Internationalization" es una palabra demasiado larga para el gusto americano, por otra parte muy dado a los acrónimos. Por esta razón se utiliza también esta "extraña" abreviatura: I18N, donde 18 se refiere a los caracteres entre la primera y última letra de la palabra i-nternationalizatio-n.
[2] Por ejemplo, en el SO Windows 98,
la administración de estas tablas está en el Panel de Control
![]() Configuración
Regional, donde existen opciones para seleccionar la configuración correspondiente a 75 localismos diferentes.
Configuración
Regional, donde existen opciones para seleccionar la configuración correspondiente a 75 localismos diferentes.
[3] Ya hemos señalado que esta diferencia es la base de la denominación números de "punto flotante" (floating point) o "coma flotante" según la convención que se utilice.
[4] Antes de la implantación del Euro como moneda única en la CEE.
[5] Antes de la implantación del sistema decimal.
[6] Del manual Borland "Standar C++ Library Help".
[7] En lo que sigue utilizaremos indistintamente los vocablos español faceta e inglés "facet" para referirnos a estas clases.
[8] El consorcio X/Open, actualmente
conocido como Open Group ![]() www.opengroup.org/ es una
asociación nacida en 1995 que agrupa a decenas de fabricantes relacionados con
la industria informática, Universidades y otros centros de investigación
interesados en facilitar el proceso de integración de las nuevas tecnologías
de la información en las empresas. La piedra angular de este proceso
es la interoperabilidad entre las diversas herramientas y plataformas de
software. Un paradigma, que en el propio consorcio define como "Boundaryless Information Flow",
que elimine las dificultades que actualmente originan a las empresas pérdidas
anuales de centenares de millones de dólares en oportunidades perdidas y les
hace gastar billones debido a la falta de una infraestructura integrada en su propia información.
www.opengroup.org/ es una
asociación nacida en 1995 que agrupa a decenas de fabricantes relacionados con
la industria informática, Universidades y otros centros de investigación
interesados en facilitar el proceso de integración de las nuevas tecnologías
de la información en las empresas. La piedra angular de este proceso
es la interoperabilidad entre las diversas herramientas y plataformas de
software. Un paradigma, que en el propio consorcio define como "Boundaryless Information Flow",
que elimine las dificultades que actualmente originan a las empresas pérdidas
anuales de centenares de millones de dólares en oportunidades perdidas y les
hace gastar billones debido a la falta de una infraestructura integrada en su propia información.
[9] La arquitectura de locales y facet, tal como se utilizan en C++, son creación de Nathan Myers. Su inclusión Estándar se debe a una propuesta inicial de él mismo al Comité de Estandarización.
[10] En algunos compiladores (por ejemplo MS Visual C++) setlocale es
también un pragma de compilación (![]() 4.9.10i).
4.9.10i).
[11] P.J. Plauger es el autor de la Librería Estándar C++ incluida en el compilador MS Visual C++, v5.0. Ha trabajado en los comités de los estándares ISO C, WG14 y en el comité J16 de C++.
[12] Según tengo entendido, esta convención también ha cambiado en la última versión de la Gramática Española (presentada oficialmente el 10 de Diciembre de 2009). Sin embargo, he mantenido la redacción original porque la situación descrita es perfectamente ilustrativa.